딥러닝과 머신러닝의 관계
우선, 딥러닝은 머신러닝의 한 종류이다. 두 단어 모두 ‘자동으로 학습하는 알고리즘’을 뜻한다. 머신러닝은 딥러닝을 포함하는 개념이지만 최근 머신러닝이라는 말은 딥러닝을 제외한 나머지 머신러닝 기술들을 지칭하기 위해 사용되는 측면이 크다.

딥러닝과 머신러닝의 차이
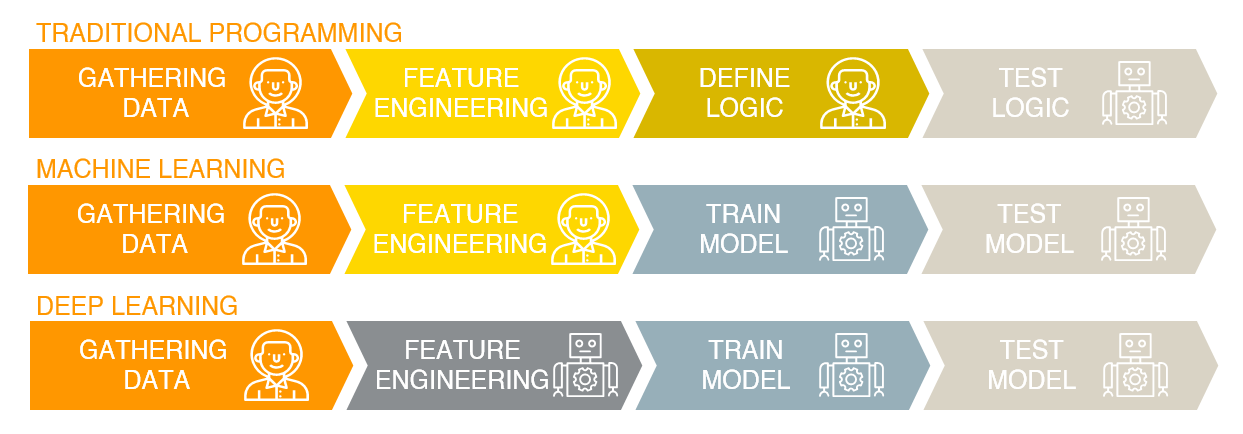
머신러닝은 크게 다음과 같은 과정을 거치게 된다.
데이터 수집(Gathering Data) – 변수 가공(Feature Engineering) – 모델 학습(Train Model) – 모델 평가(Test Model)

전통적 프로그래밍(Traditional Programming)에서는 사람이 알고리즘을 직접 작성하였다면, 머신러닝을 통해서는 그럴 필요 없이 모델을 자동 생성할 수 있다.
머신러닝에서 한 발 더 나아가, 데이터를 가공하는 데 있어 사람의 개입을 줄여 변수 가공(Feature Engineering) 과정을 생략하고도 좋은 성능을 낼 수 있게 되었는데 이 방법이 바로 딥러닝이다.
딥러닝과 머신러닝 중 어느 것을 사용해야 할까?
최신 기술이라고 해서 모든 데이터에 딥러닝이 더 적합하다고 얘기할 수는 없다. 다음과 같은 논점에서 딥러닝을 사용해야 하는지 머신러닝을 사용해야 하는지 판단할 수 있다.
- 딥러닝은 데이터 사이즈가 아주 클 때 적합하다. 작은 사이즈의 데이터인 경우, 특히 변수가 작은 경우는 머신러닝이 적합하다.
- 딥러닝은 고사양 컴퓨터와 상당한 학습시간을 필요로 한다.
- 데이터에 대한 도메인 지식이 없고, 변수(feature)에 대한 이해가 부족한 경우 변수 가공이 불필요한 딥러닝이 적합하다.
- 딥러닝은 이미지 분류, 자연어 처리, 음성인식 등의 복잡한 문제에 성능이 좋은 경향이 있다.
붓꽃 분류하기 예시
붓꽃 데이터(Iris Dataset)는 Setosa, Virginica, Versicolor 3개의 붓꽃 품종을 구분해내는 것을 목적으로 만들어졌으며, 머신러닝을 경험해볼 수 있는 아주 간단한 장난감 데이터(toy data set)이다.

이 데이터에 빗대어 전통적인 프로그래밍(Traditional Programming), 머신러닝(Machine Learning), 딥러닝(Deep Learning)에서 각각 어떻게 붓꽃을 분류할 수 있는지 비교해보자.
- 전통적인 프로그래밍(Traditional Programming)
- 데이터 수집: 붓꽃 품종에 관련된 많은 데이터를 수집한다.
- 변수 가공: 붓꽃 품종은 '꽃잎(Petal)의 길이'와 '꽃받침(Sepal)의 길이'로 구분 할 수 있다는 변수를 알아낸다.
- 로직 정의: 전문가에게 부탁하거나 본인이 분석하여 꽃받침의 길이가 몇cm 이상이면 Versicolor, 이하면 Setosa라는 여러 세트의 rule들을 정의하여 모델을 만든다.
- 모델 평가: 데이터를 모델에 넣어 정확도가 어느정도 인지 확인해본다.
- 머신러닝(Machine Learning)
- 데이터 수집: 붓꽃 품종에 관련된 많은 데이터를 수집한다.
- 변수 가공: 붓꽃 품종은 '꽃잎의 길이'와 '꽃받침의 길이'로 구분할 수 있다는 변수를 알아낸 뒤 해당 변수의 데이터를 잘 정리한다.
- 모델 학습: Decision Tree, SVM 등 다양한 알고리즘에 데이터만을 입력해보며 적합한 모델을 생성한다.
- 모델 평가: 학습에 사용되지 않은 데이터를 최종 모델에 넣어 정확도가 어느정도 인지 확인해본다.
- 딥러닝(Deep Learning)
- 데이터 수집: 붓꽃 품종에 관련된 많은 이미지 데이터를 수집한다.
- 변수 가공: 변수(feature)는 모델에서 자동 생성된다.
- 모델 학습: 이미지 데이터를 입력하여 다양한 네트워크를 구성해보고 적합한 모델을 생성한다.
- 모델 평가: 학습에 사용되지 않은 이미지 데이터를 최종 모델에 넣어 정확도가 어느 정도 인지 확인해본다.
전통적 프로그래밍에서 머신러닝, 딥러닝으로 갈수록 사람이 직접 알고리즘을 작성하고, 변수 선택을 하는 일련의 과정들이 자동화되는 것을 볼 수 있다.
'IT > ML' 카테고리의 다른 글
| K-Fold Cross Validation(교차검증) 쉽게 이해하기 (0) | 2020.10.19 |
|---|---|
| Training, Validation and Test sets 차이 및 정확한 용도 (훈련, 검정, 테스트 데이터 차이) (2) | 2020.10.19 |
| 머신러닝 편향-분산 트레이드오프(Bias-variance tradeoff) 쉽게 이해하기 (0) | 2020.09.22 |
| 차원의 저주 KNN으로 쉽게 이해하기 (0) | 2020.08.24 |
| 인공지능, 머신러닝 그리고 딥러닝의 뜻 알아보기 (0) | 2020.08.06 |



