Boosting기법은 머신러닝을 사용할 시, 퍼포먼스가 좋기 때문에 반드시 돌려봐야 하는 알고리즘 중 하나이다. Decision tree를 발전시킨 방법인 방법으로 관련 내용은 다음을 참고하면 좋다.
의사결정트리(Decision Tree) 회귀트리, pruning 쉽게 이해하기
결정 트리 학습법(decision tree learning)은 머신러닝 학습 방법 중, 결과 데이터(output variable)로 학습시키는 지도 학습(supervised learning)에 해당된다. Output variable 이 연속적인 값일 경우(월급,..
modern-manual.tistory.com
의사결정트리 배깅(Bagging)과 랜덤포레스트(Random Forest) 쉽게 이해하기
Bagging과 random forests는 의사결정 트리(decision tree)를 발전시켜 더 좋은 예측 모델을 만들기 위해 사용되는 기법이다. 배깅(Bagging) Bootstrap aggregation을 줄여 bagging이라고 부른다. Bootstrap으..
modern-manual.tistory.com
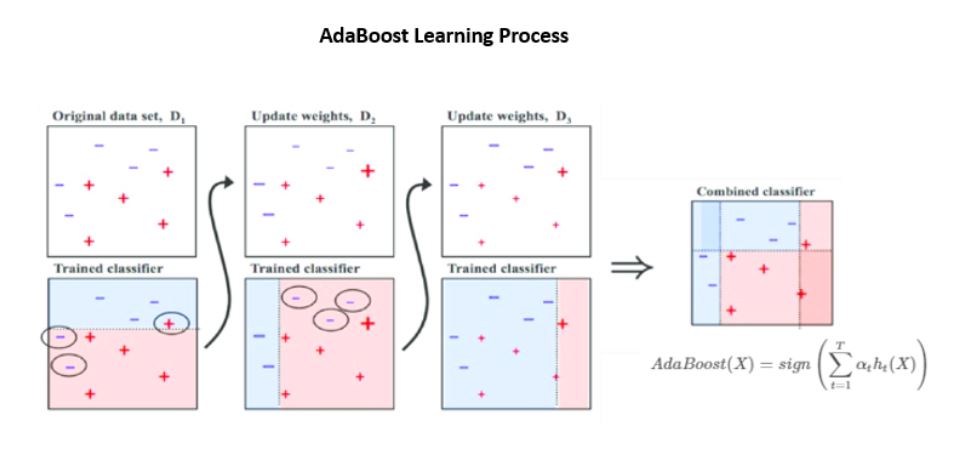
부스팅(Boosting)
Random forest는 독립적인 트리들로 구성되어 있다면, Boosting은 각각 이전 트리에 영향을 받아 연속적인 형태로 구성된다. 이때 트리들은 한 두 depth로 이뤄진 매우 작은 트리이다. 이렇게 작은 트리들을 1000개 이상 사용하여 모델링하면 대체로 Random forest보다도 더 좋은 성능을 나타낸다. 각 트리는 이전의 트리에서 잘 학습하지 못했던 부분에 대해 더 가중치를 두어 학습하게 되며, 작은 트리 각각은 성능이 좋지 않지만(weak learners) 전체적으로는 아주 강력한 성능을 보이게 된다.
Tuning parameters
1. number of trees B
- B개의 트리를 만들며, cross validation을 통해 B를 선택한다.
2. shrinkage parameter $\lambda$
- Boosting 알고리즘이 학습하는 속도를 조절하는 파라미터로 0.01, 0.001을 주로 사용한다.
3. number of splits d
- 트리의 크기를 결정하는 분기 개수 d는 작은 숫자로 설정한다. 딱 한 개의 분기를 갖는 d=1이잘 작동하는 경우도 많다.
Boosting Algorithm
B개의 tree를 학습시키기 위해, 각 iteration마다 d split을 가지는 트리 $\hat{f}^b$를 training data $(X, r)$에 대해 학습시킨다. 초기값을 $r=y$로 세팅하지만, 여기서 정답 $y$가 아닌 오차 $r$을 학습시키는 점을 주의해서 보면 된다. 학습된 새 트리 $\hat{f}^b(x)$를 기존 트리 $\hat{f}(x)$에 더하여 트리를 업데이트하고, 새 트리로 줄어든 만큼의 오차 $\hat{f}^b(x_i)$를 각 데이터 $r_i$마다 반영해준다.

결과를 보면 Boosting을 사용하여 parameter값을 잘 조정해 주면 Random forest 보다 더 좋은 성능을 보이는 것을 확인할 수 있다.

파이썬으로 adaboost 학습해보기
Adaboost는 adaptive boosting의 약자로 대표적인 boosting 알고리즘이다. 간단히 이를 사용해보는 코드는 다음과 같다.
# 참고: https://www.datacamp.com/community/tutorials/adaboost-classifier-python
# Load libraries
from sklearn.ensemble import AdaBoostClassifier
from sklearn import datasets
from sklearn.model_selection import train_test_split
from sklearn import metrics
# Load data
iris = datasets.load_iris()
X = iris.data
y = iris.target
# Split dataset into training set and test set
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3) # 70% training and 30% test
# Create adaboost classifer object
abc = AdaBoostClassifier(n_estimators=50,
learning_rate=1)
# Train Adaboost Classifer
model = abc.fit(X_train, y_train)
# Predict the response for test dataset
y_pred = model.predict(X_test)
# Model Accuracy, how often is the classifier correct?
print("Accuracy:",metrics.accuracy_score(y_test, y_pred))'IT > ML' 카테고리의 다른 글
| SVM 쉽게 이해하기 - (2) Support Vector Machine(서포트벡터머신) (0) | 2020.11.10 |
|---|---|
| SVM 쉽게 이해하기 - (1) Maximal Margin Classifier와 Support Vector Classifier (0) | 2020.11.10 |
| 의사결정트리 배깅(Bagging)과 랜덤포레스트(Random Forest) 쉽게 이해하기 (0) | 2020.11.03 |
| Bootstrap sampling (Bootstrapping, 부트스트랩 샘플링) 쉽게 이해하기 (0) | 2020.11.03 |
| 의사결정트리(Decision Tree) 분류트리, Gini, Entropy 쉽게 이해하기 (0) | 2020.11.03 |



